Machine Learning¶
Accessing the MQS Graph Neural Network (GNN) Model Library through the Cebule API¶
We have now added an updated and further developed Graph Neural Network (GNN) model to the Cebule Application Programming Interface (API) where several endpoints allow to create/extend/delete a data set, train a GNN model and use the trained model as a prediction model. The endpoints of the API can be accessed via the Python SDK (https://gitlab.com/mqsdk/python-sdk) with the task types:
- GNN_DATASET_CREATE
- GNN_DATASET_DELETE
- GNN_DATASET_EXTEND
- GNN_TRAIN
- GNN_PREDICT
Here is an example to create a dataset for a training task:
Create a training task with Cebule for a GNN
data = json.dumps({
"dataset_name": "dataset_a",
"target_val": True
})
task_dataset_create = session.cebule.create_task("GNN Create Dataset Example",
TaskType.GNN_DATASET_CREATE,
data)
The following code snippet shows how to extend this dataset with some data once the previous task has completed:
# Create your list of molecule SMILES along with the target property values
smiles_list = ["C(=O)=O", "[C-]#[O+]", "C1=C2C(=CC(=C1Cl)Cl)OC3=CC(=C(C=C3O2)Cl)Cl"]
# The values here are dummy numbers for this example.
val_list = [5.0, 2.0, 3.0]
data = json.dumps({
"dataset_name": "dataset_a",
"molecule_chunk": {
"smiles": smiles_list,
"val": val_list
}
})
session.cebule.create_task("GNN Extend Dataset Example",
TaskType.GNN_DATASET_EXTEND,
data)
You can repeatedly call the above task to construct your dataset in chunks.
To view chunks of your created dataset (from a start index to an end):
data = json.dumps({
"dataset_name": "dataset_a",
"start": 1,
"end": 3
})
session.cebule.create_task("GNN Get Dataset Example",
TaskType.GNN_DATASET_GET,
data)
The above task will return the last two molecules out of the 3 which were added to "dataset_a".
Deleting a dataset again is also possible:
data = json.dumps({"dataset_name": "dataset_a"})
session.cebule.create_task("GNN Delete Dataset Example",
TaskType.GNN_DATASET_DELETE,
data)
After the dataset create/extend tasks have been completed you can start training the GNN model:
data = json.dumps({"dataset_name": "dataset_a",
"model_name": "model_a",
"hyperparameters": {"epochs": 75}
})
task_gnn_train = session.cebule.create_task("Train GNN Example",
TaskType.GNN_TRAIN,
data)
And when the training task has been completed, you will be able to apply the GNN model for predicting the target property for a dataset with new molecular structures:
You can utilize the MQS GNN library for example as a toxicity classifier, or as a Hamiltonian generator.
The Hamiltonian generator allows to retrieve the needed problem description of large molecules (approx. 500 g/mol) to be solved by digital annealers, quantum annealers or variational quantum eigensolver (VQE) methods. A complete Jupyter notebook with all the TaskType examples above can be found under the following link: https://gitlab.com/mqsdk/python-sdk/-/blob/main/notebooks/8_GNN.ipynb
Please contact us via contact (at) mqs (dot) dk, if you would like to have an onboarding session how the combination of our quantum chemistry models and the GNN model can be utilized for your use-case application.
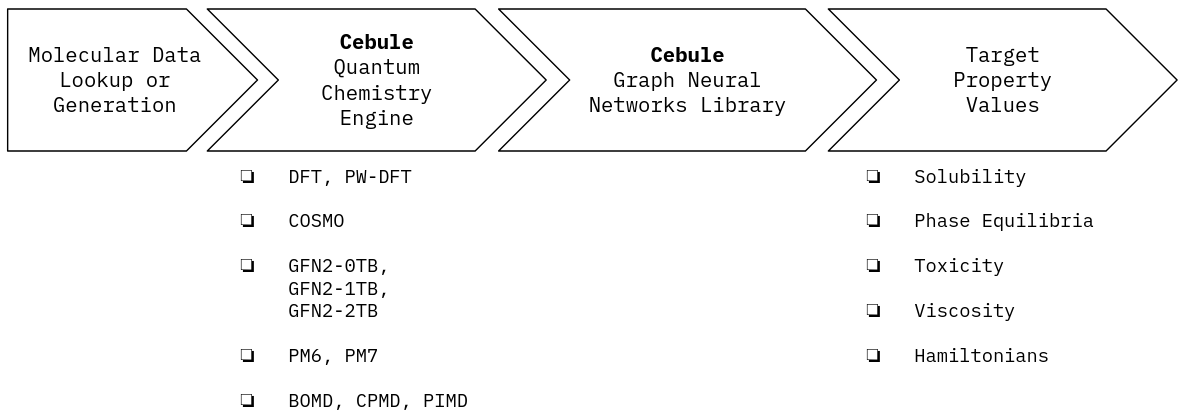
The visualisation at at the top of this blog article shows the individual steps of this holistic pipeline and the framework allows to tackle many different pharma, biopharma, chemical and materials applications. The following table gives an overview of the domain specific use-cases:
| Use-case Domain → | Formulation Development & Product Design | Upscaling & Process Simulations | Materials Design |
|---|---|---|---|
| Properties → | Solubility, Stability, Toxicity, Viscosity | Vapour-Liquid Equilibrium (VLE) | HOMO-LUMO Gap, Ground & Excited States |
| Binding Analysis | Liquid-Liquid Equilibrium (LLE) | Seebeck Coefficient | |
| Solid-Liquid Equilibrium (SLE) | Solubility, Phase Stability | ||
| Use-case Examples → | (Bio)Pharma Solubility in Multi-compound Mixtures | Crystallizer Design for Purification Processes | OLED Materials |
| Toxicity Checks in Pharma & Chemical Product Development | Solvents Analysis for CO2 Capture & CO2 Utilization Processes | Energy Storage Materials | |
| Human, Animal and Environmental Safety | Liquid-Liquid Chromatographic Separation | High-Entropy Alloys | |
| Beauty Care Product Design | Property data for Computational Fluid Dynamics (CFD) | Catalyst Design | |
| Integrated Drug Discovery & Formulation Analysis | Anti-corrosion and Functional Coatings |
In the next section we present an example how to predict the HOMO-LUMO gap with the GNN model via Kubeflow (https://dashboard.mqs.dk/subscriptions). Kubeflow is the second option apart from the MQS Python SDK how to utilize the MQS model library.
Grap Neural Network (GNN)¶
In the previous tutorial, we saw how a fine-tuned DelFTa EGNN model 1 on PCB data from the PubChemQC PM6 quantum chemistry dataset 2 can result in more accurate HOMO-LUMO gap (toxicity indicator) prediction of PCB molecules. This also eliminated outlier predictions that were previously present with a pre-trained DelFTa model on the QMugs dataset 3.
In this tutorial, we first present a novel graph neural network: a Matrix-completed Graph Neural Network (MCGNN); and compare its PCB HOMO-LUMO gap prediction to the DelFTa model by first training it on the ~2 million molecules in QMugs, and then fine-tuning it with PCB data from PubChemQC PM6. This MCGNN slightly outperforms DelFTa on the PCB dataset after fine-tuning.
Furthermore, we then demonstrate how to fine-tune your own MCGNN and DelFTa models on Kubeflow, which is incorporated in the MQS Dashboard Machine Learning tier. One can then run predictions with the fine-tuned model on arbitrary molecules. All parts of the ML pipeline have been modularized to allow the user to tailor the models based on their use-case and dataset choice.
The following molecular properties/information can be predicted with our models:
- HOMO-LUMO gaps - available via MCGNN and DelFTa with MQS Dashboard ML subscription
- Hamiltonians (total energy functions)
- Activity coefficients
- Critical physical properties (critical temperature, critical pressure, acentric factor)
- Solubilities
- Phase equilibria (VLE, SLE, LLE)
Contact us for more information with respect to these properties. Currently only the HOMO-LUMO gap model is provided in the ML tier of the MQS Dashboard.
Currently the following data sets can be accessed via the MQS Dashboard:
- PubchemQC PM6
- QMugs
GNN model library overview¶
Graph Neural Networks (GNNs) are neural networks specifically designed to operate on graph-structured data. A molecule can for example be mapped to a GNN where a message-passing layer facilitates information exchange and aggregation between connected nodes (atoms), enabling nodes to update their representations based on messages received from neighboring nodes (bonded atoms). This enables effective modelling of relational structures and improves the network’s ability to learn from graph-structured data.
Fine-tuning a DelFTa model with PCB data
We have shown in the Database section how a pre-trained DelFTa EGNN model 1 on the QMugs dataset 3 can be applied to predict the HOMO-LUMO gap of PCB molecules. The data points were placed in a classification diagram based on the HOMO-LUMO gap and the rotational angle between the two ring structures. A dioxin toxicity boundary was defined to classify if the PCB molecules were within this specific toxicity limit.
We also compared these DelFTa prediction results to the PubChemQC PM6 2 HOMO-LUMO gap values and could identify outliers.
In this tutorial, we fine-tune the DelFTa EGNN on PubChemQC PM6 PCB molecule data to more accurately predict the HOMO-LUMO gap of PCBs and treat the outliers. We assume the values in the PubChemQC PM6 dataset (accessible via the MQS Search API) are closer to the true experimental values than the QMugs ones, since some values predicted by the DelFTa model (trained only on the QMugs dataset) showed large deviations from the rest of the data points as demonstrated in our previous tutorial.
To start, we will use the following MQS Search API query to grab 194 PCBs from the PubchemQC PM6 and QMugs datasets:
From the resulting PCB data, we only use PubchemQC PM6 data since the DelFTa model has already been trained with the QMugs dataset. As shown in the previous tutorial, we can extract the HOMO-LUMO gap value and the 3D atom coordinates of the molecules from this data.
We fine-tune the pre-trained DelFTa model using the atomic numbers, 3D coordinates of atoms, and bond information of each PCB. While it is not possible for us to remove the QMugs outlier datapoints from the model's training without completely retraining it, we can still treat these outliers solely by fine-tuning; we chose a learning rate of 2.0 * 10-3 to strike a balance between giving weight to the PubchemQC PM6 PCB datapoints while also retraining the model's original QMugs training to a good extent.
Example: DelFTa Model prediction performance comparison for PCB molecules against PM6 data¶
Model prediction performance comparison for PCB molecules
We ran predictions with the fine-tuned DelFTa model on all 194 PCB molecules, and compared the results to the HOMO-LUMO Gap values from the PubChemQC PM6 data. This is shown in Figure 1, in which the x-axis represents different PCB molecules, and the y-axis represents HOMO-LUMO gap values in electronvolt (eV):
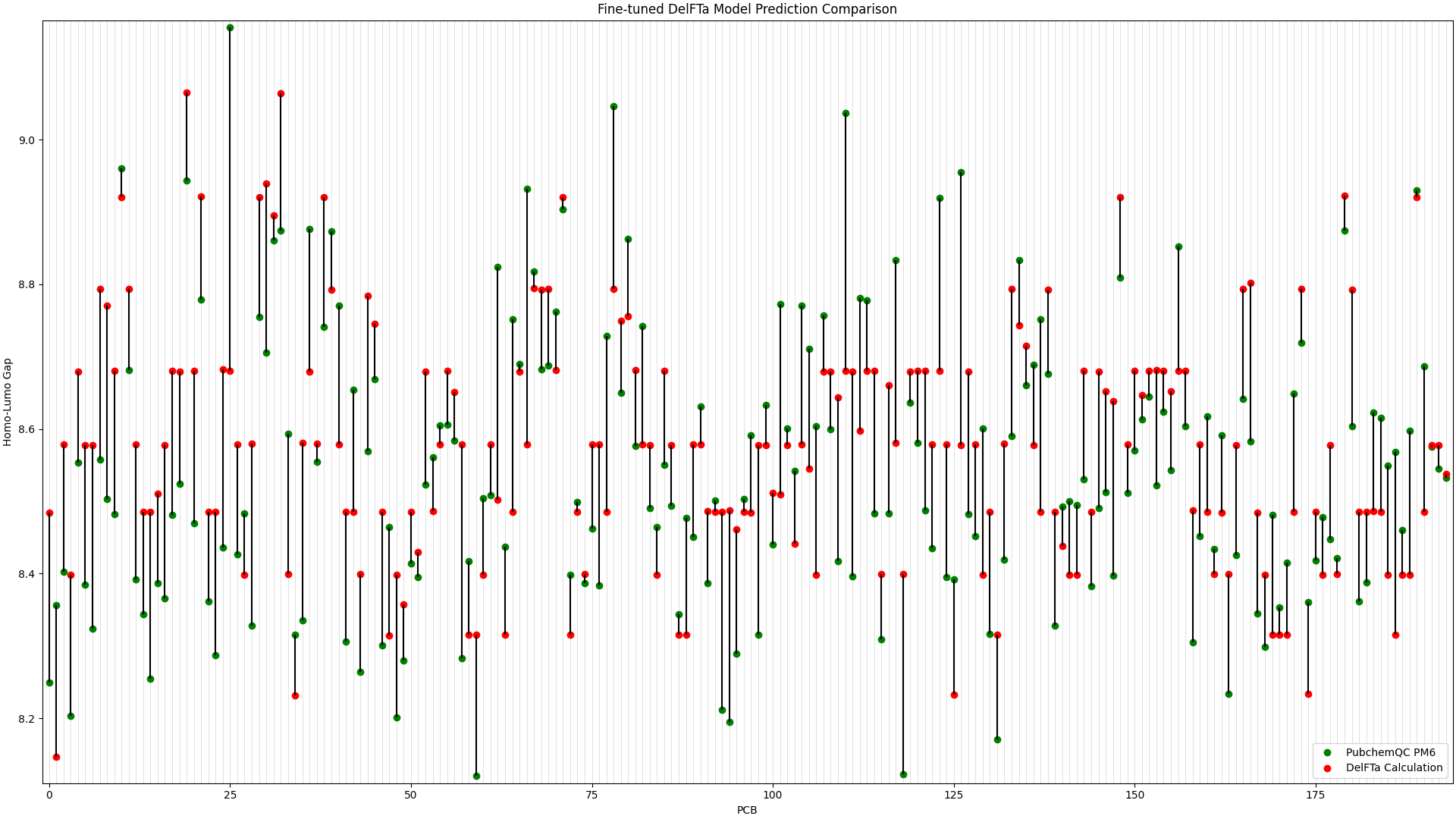 Figure 1: Fine-tuned DelFTa Model Predictions
Figure 1: Fine-tuned DelFTa Model Predictions
To illustrate the improvement in the above picture with the fine-tuned DelFTa model, we can compare the above figure to the predictions from a pre-trained DelFTa model:
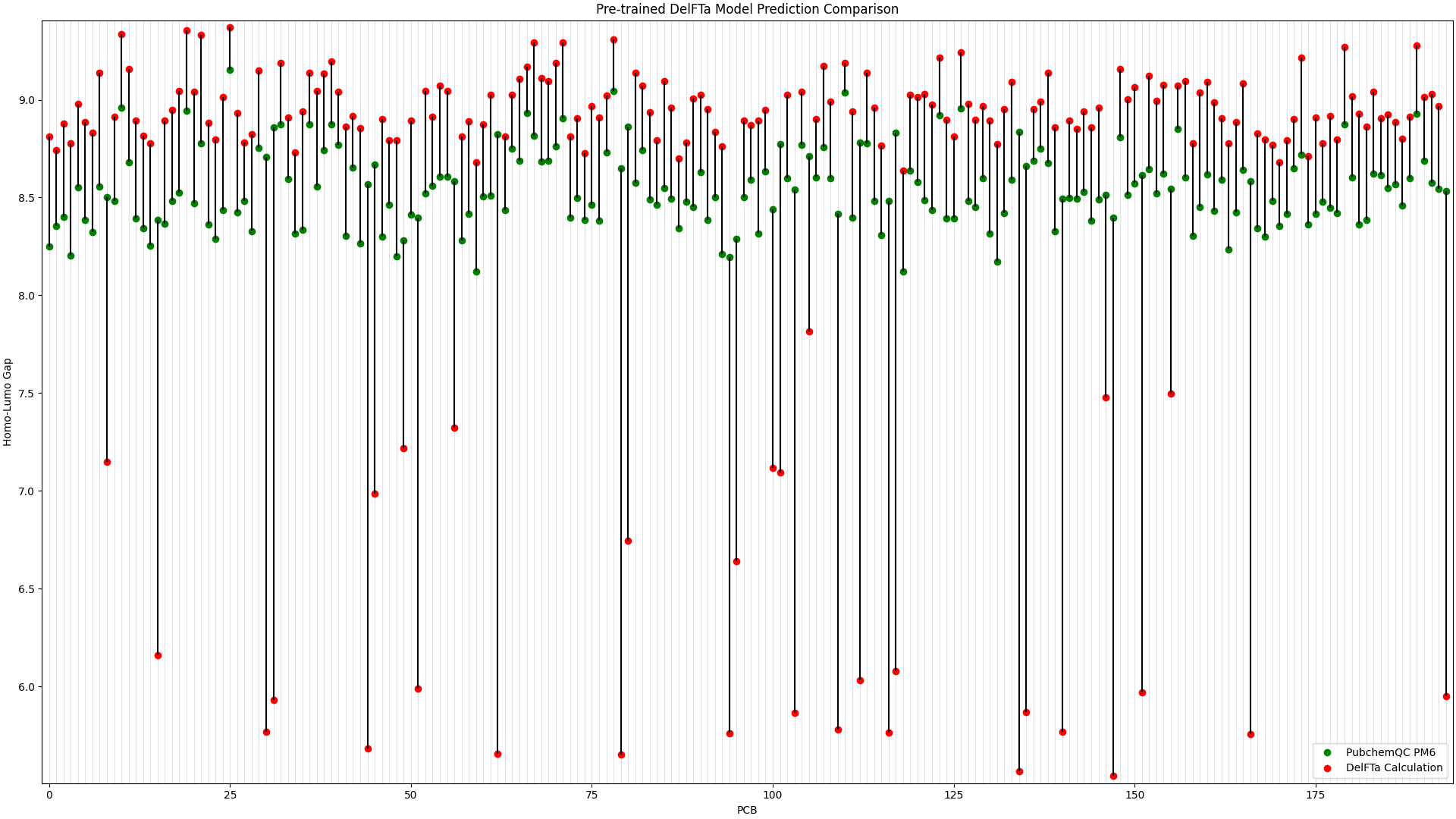 Figure 2: Pre-trained DelFTa Model Predictions
Figure 2: Pre-trained DelFTa Model Predictions
As you can see in Figure 1 (note that the y-axis scale is different from Figure 2), the pre-trained DelFTa model had numerous outliers in prediction in which the model underpredicted (in contrast to it overpredicting otherwise) and was off by well over 1eV, however these outliers are not seen in Figure 2 with the fine-tuned model.
In terms of accuracy, in our test data of 39 molecules (none of which were outliers) that we did not fine-tune the model with, the pre-trained DelFTa model had a mean absolute error of 0.41 eV, while the new fine-tuned model has significant improvement with a mean absolute error of 0.11 eV.
Note that the 100 PCBs analyzed in the previous tutorial are a subset of the 194 displayed here.
Clearly, training a DelFTa with PubChemQC PM6 PCB data improved its ability to predict the HOMO-LUMO gaps of PCBs. To demonstrate model fine-tuning and prediction in a lightweight manner, we did use a small dataset of 194 molecules in this experiment, but the same procedure can be applied to more extensive datasets for other experiments as well.
We hope we showed you that combining the DelFTa model together with an additional dataset for fine-tuning can be of value for interesting machine learning studies with molecular quantum information.
Example: GNN performance compared to DelFTa for PCB molecules¶
GNN performance compared to DelFTa for PCB molecules
We evaluate the performance of both the MQS GNN implementation trained on HOMO-LUMO Gap data from the QMugs dataset and a fine-tuned GNN on the PubchemQC PM6 data for the 194 PCBs analyzed in the previous blog article.
The PCB prediction performance of the fine-tuned and pre-trained DelFTa models from the previous blog article is in Figure 1 and Figure 2 below.
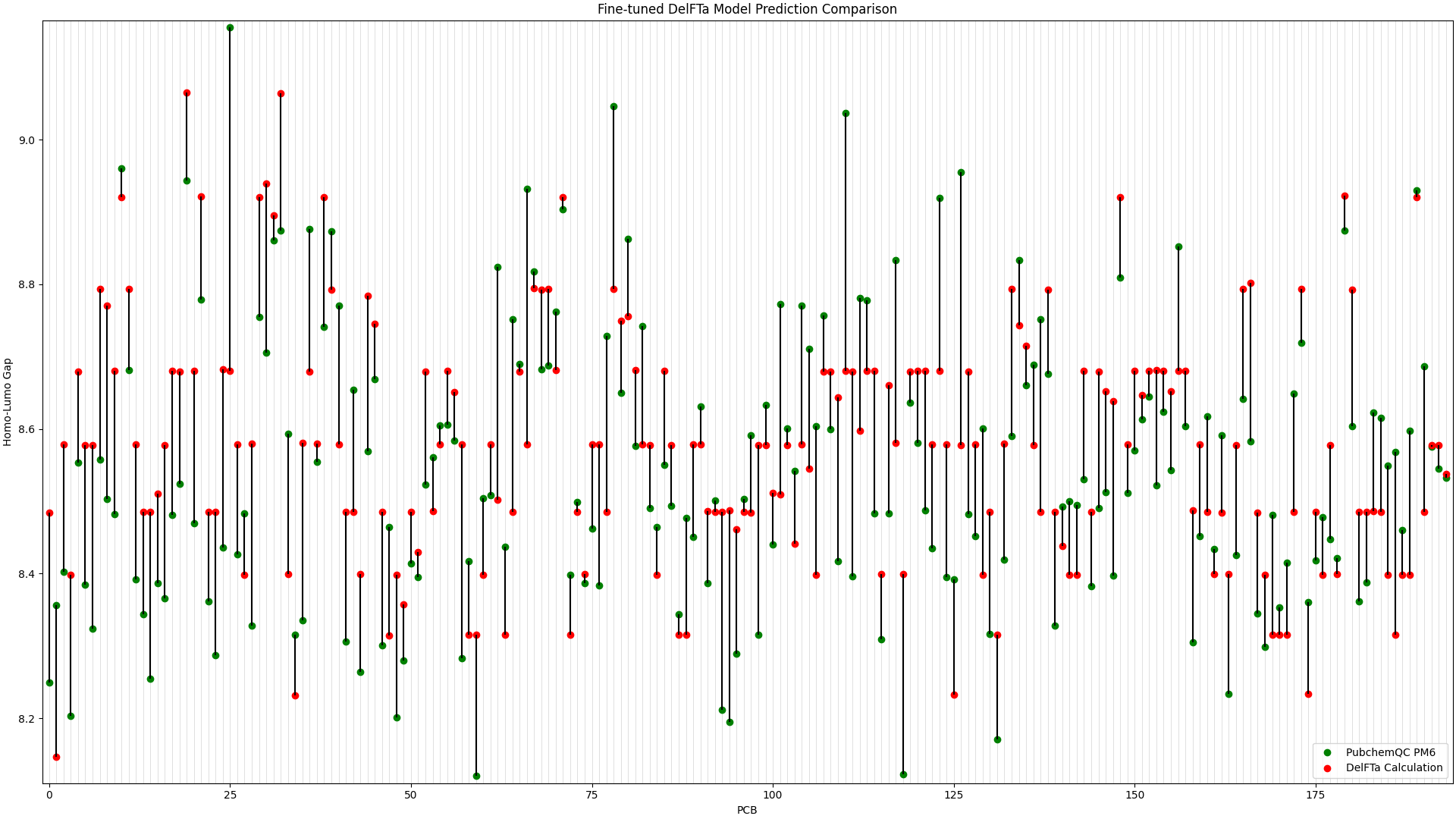 Figure 1: Fine-tuned DelFTa Model Prediction Comparison
Figure 1: Fine-tuned DelFTa Model Prediction Comparison
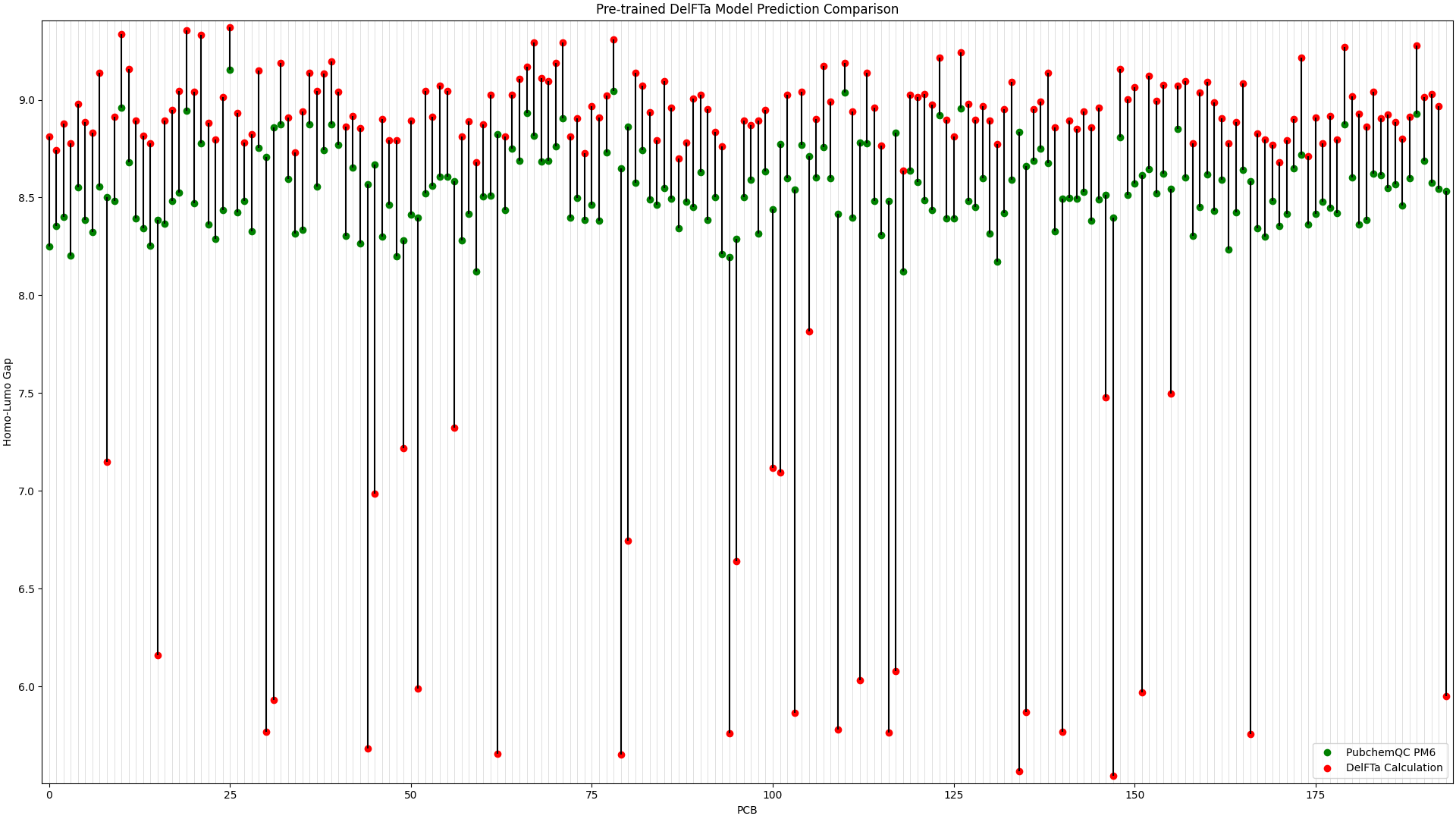 Figure 2: Pre-trained DelFTa Model Prediction Comparison
Figure 2: Pre-trained DelFTa Model Prediction Comparison
Recall that the test data of 39 molecules (none of which were outlier predictions) does not hold any training data points from the fine-tuning step. The pre-trained DelFTa model had a mean absolute error for the test data of 0.41 eV, while the fine-tuned DelFTa model had a mean absolute error of 0.11 eV.
We evaluate the fine-tuned GNN and pre-trained (trained only on QMugs) models in the same way in Figure 3 and Figure 4 below.
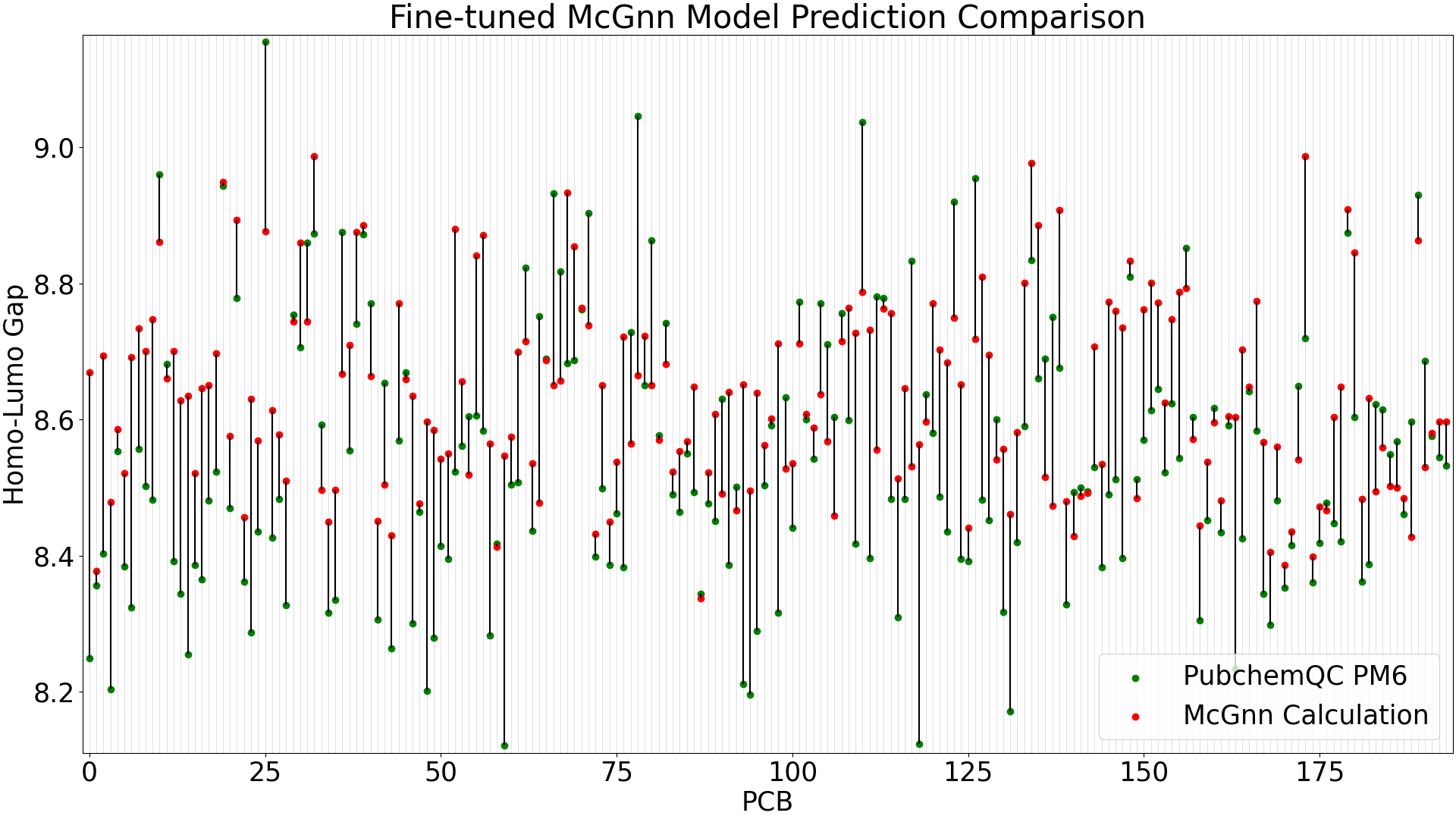 Figure 3: Fine-tuned GNN Model Prediction Comparison
Figure 3: Fine-tuned GNN Model Prediction Comparison
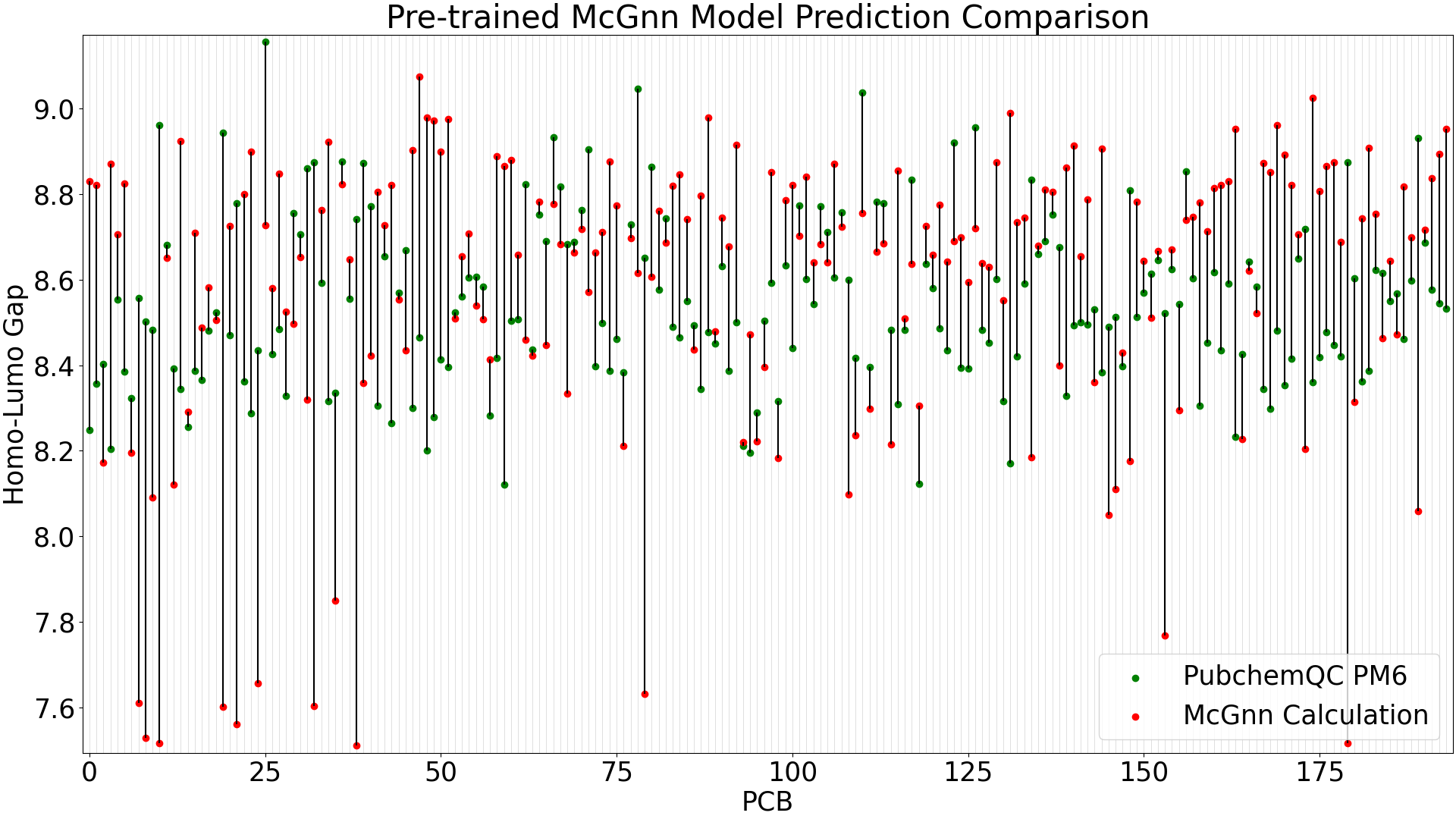 Figure 4: Pre-trained GNN Model Prediction Comparison
Figure 4: Pre-trained GNN Model Prediction Comparison
When running predictions with the test data (39 molecules), the pre-trained GNN model shows a mean absolute error of 0.35 eV, while the fine-tuned MCGNN has significant improvement with a mean absolute error of 0.10 eV.
The larger-error predictions in the pre-trained GNN plot (Figure 4) are still less than DelFTa's pre-trained model predictions (Figure 2), and we can see that the accuracy of both the pre-trained and fine-tuned GNN models outperform (pre-tained) and slightly outperform (fine-tuned) the DelFTa model counterparts.
Example: Fine-tuning a model via Kubeflow for toxicity predictions of PCB molecules¶
Fine-tuning a model via Kubeflow for toxicity predictions of PCB molecules
Anyone with the Machine Learning tier MQS subscription can fine-tune a GNN or DelFTa model in Kubeflow via the MQS Dashboard and choose a query to select molecules to train on. Here, we will use the following query to grab 194 PCBs from the PubchemQC PM6 and QMugs data sets (although the data for fine-tuning will be solely taken from the PubchemQC PM6 data set):
Using this query, we will fine-tune a MCGNN model to predict the HOMO-LUMO gap based on the PCBs' 3D molecular structures. The Kubeflow training pipeline will fetch the PCB data using the MQS API and then train the model with it.
To run the Kubeflow training pipeline, follow these steps from the MQS Kubeflow Dashboard:
-
Create an experiment in
Experiments (KFP) -> Create experiment, entering a name and then hittingNext:
-
Run the training pipeline
2.1. Go to
Runs -> Create run2.2. For
Pipeline, select themodel_trainingpipeline underSharedpipelines2.3. For
Experiment, select the experiment you just created2.4. Give your model an ID in
model_idso you can reference it after training. The ID cannot bedelftaormcgnn(model_nameoptions). We do not support overwriting existing model IDs with new trained models2.5. Choose between
mcgnnordelftaformodel_name. We will demonstrate training a MCGNN model2.6. Enter the PCB query above for
query. Note that datasets for fine-tuning are limited to 1000 or less molecules2.7. Enter
homo_lumo_gapfortarget_property. More properties will be supported soon.2.8. Finally, hit
Startto start the training procedure.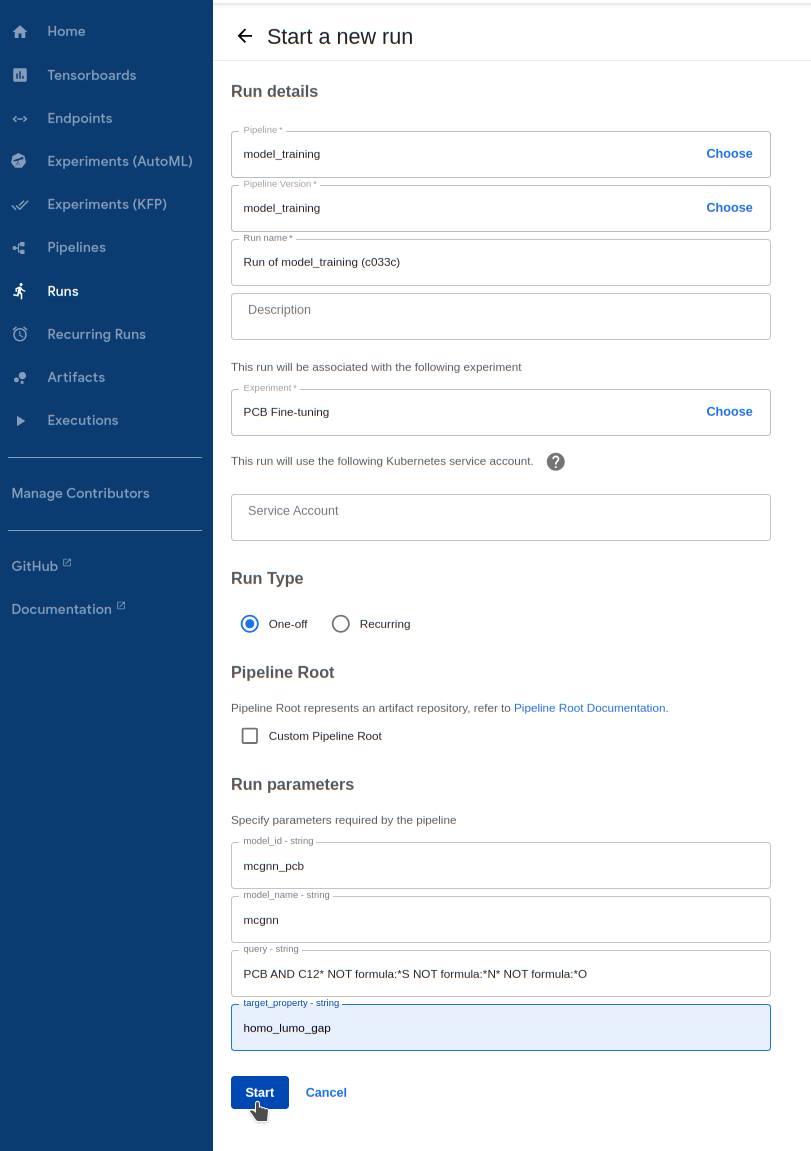
-
Wait for the training procedure to complete and display green marks on the following components. If the pipeline fails (likely due to invalid input), click on the failed component and view its
Logsto see the error message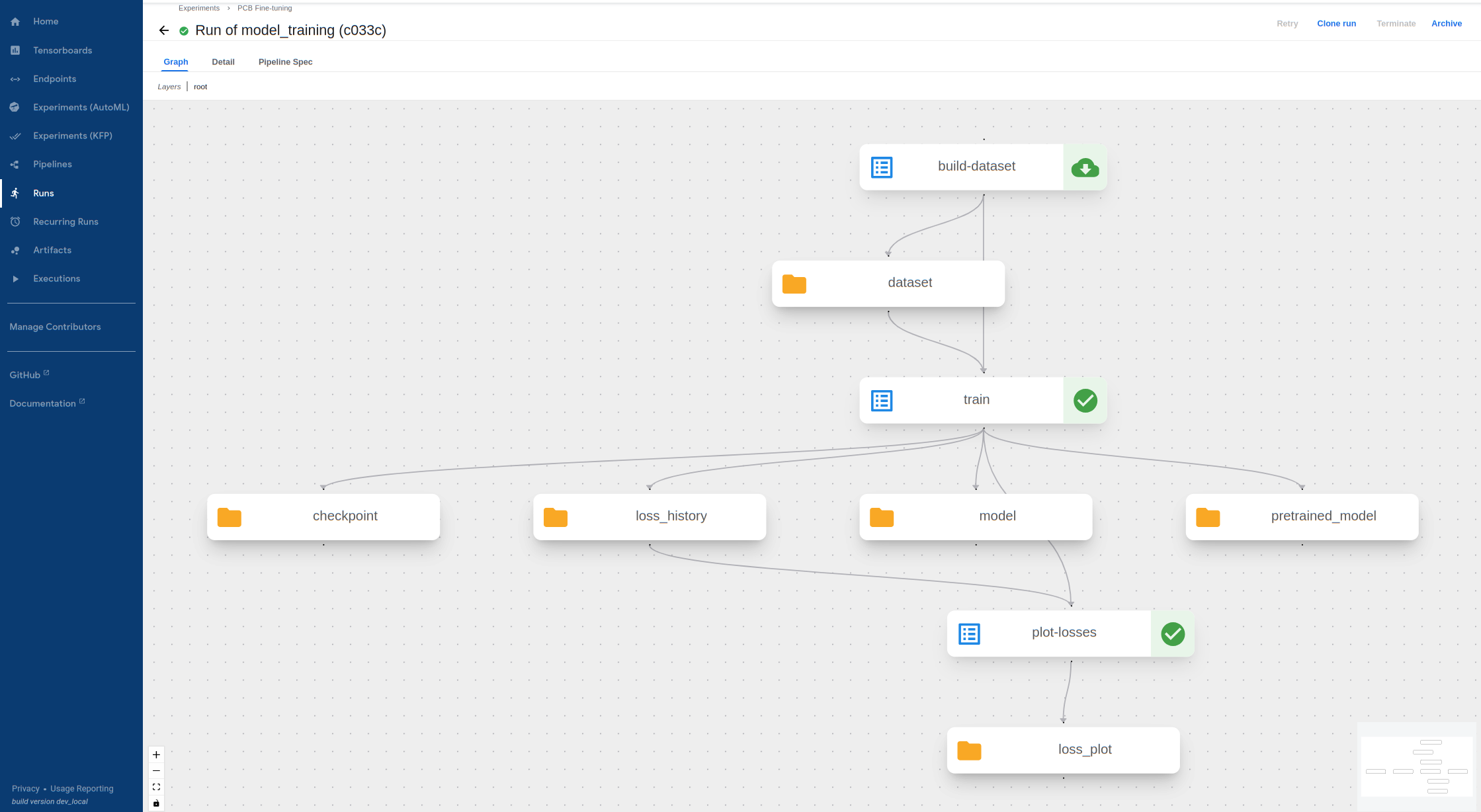
-
Visualize outputs! The successful training step creates a dataset text file, model files, as well as a loss history file and plot. Let's take a look at the loss history plot by going to
Artifactsand clicking on theURIforloss_plot: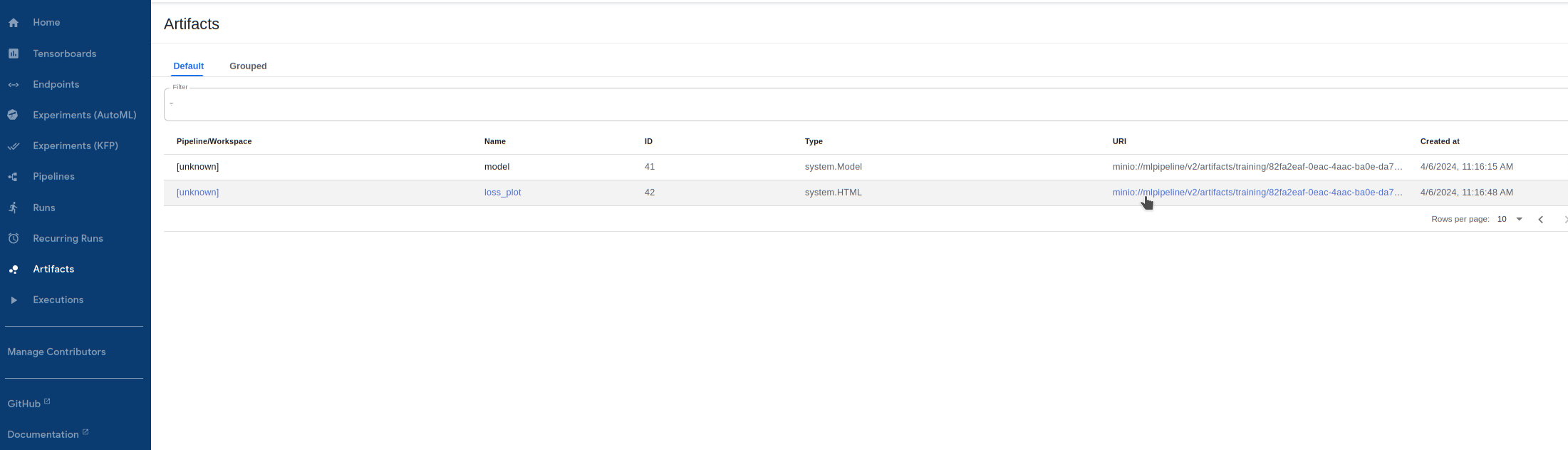
-
This will open up HTML file source code which we can save locally with
ctrl-S. A current limitation with Kubeflow is that all output files are saved as.txtfiles, so when saving this file, please change the extension of theloss_plotfile from.txtto.html. Then, view this file in browser withctrl-Oand then selecting the downloaded file. This displays a plot of training/validation mean squared error (MSE) loss versus number of training epochs: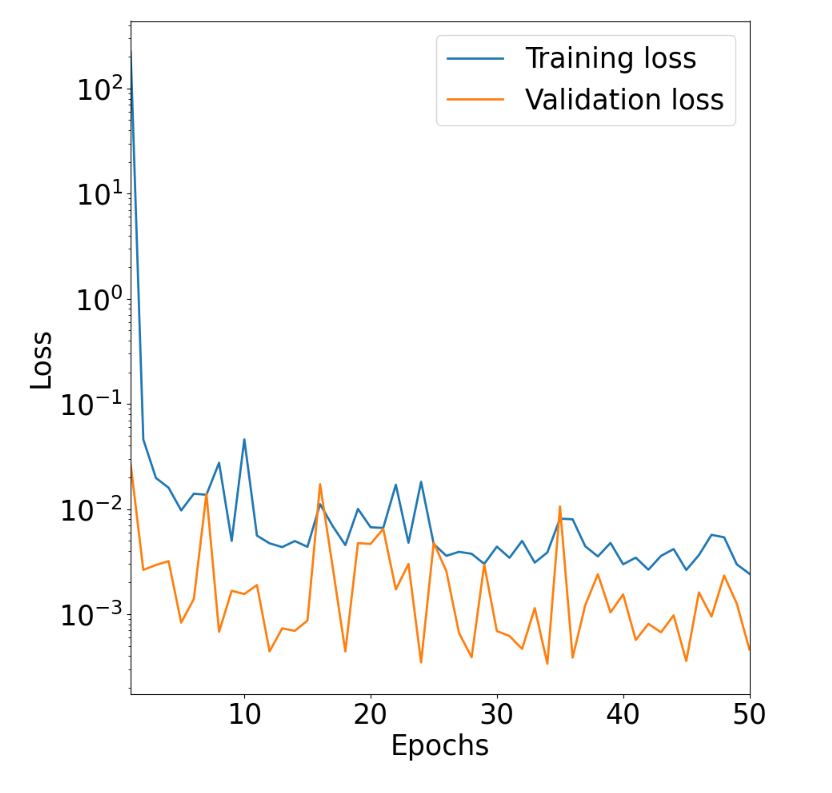
-
Similarly, you can view the
loss_historytext file by downloading it from theArtifactspage (no need to convert it to.html). Note that visualization for text and HTML files should be supported from the Kubeflow UI in the future so downloading will not be required.
Example: Prediction of toxicity of PCB molecules with trained model via Kubeflow¶
Prediction of toxicity of PCB molecules with trained model via Kubeflow
Once the model has been trained we can run a prediction with arbitrary molecules, although one has to evaluate carefully how well the model covers the prediction of molecules that are not very similar to the training data, for example molecules not being part of the same molecule class which the model has been trainined on. Figure 5 and Figure 6 show the two PCBs 2,3,3',4,4',5,5'-Heptachlorobiphenyl and 3,3',4,5-Tetrachlorobiphenyl, which we will run prediction on with the MCGNN we just fine-tuned.
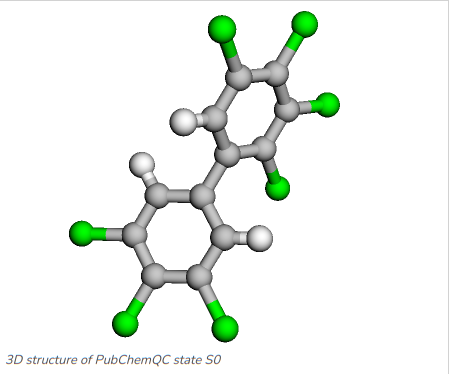
Figure 5: 2,3,3',4,4',5,5'-Heptachlorobiphenyl: C1=C(C=C(C(=C1Cl)Cl)Cl)C2=CC(=C(C(=C2Cl)Cl)Cl)Cl
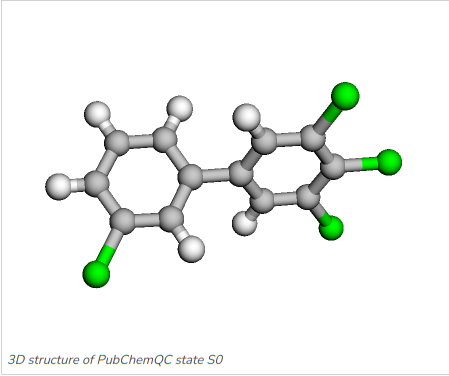
Figure 6: 3,3',4,5-Tetrachlorobiphenyl: C1=CC(=CC(=C1)Cl)C2=CC(=C(C(=C2)Cl)Cl)Cl
To select these molecules for prediction, the following comma-separated list of the PCBs' SMILES definition is applied:
The prediction pipeline will read in and geometry-optimize these molecule SMILES before predicting the HOMO-LUMO gap, which allows us to run predictions on molecules that are not in the database as well.
-
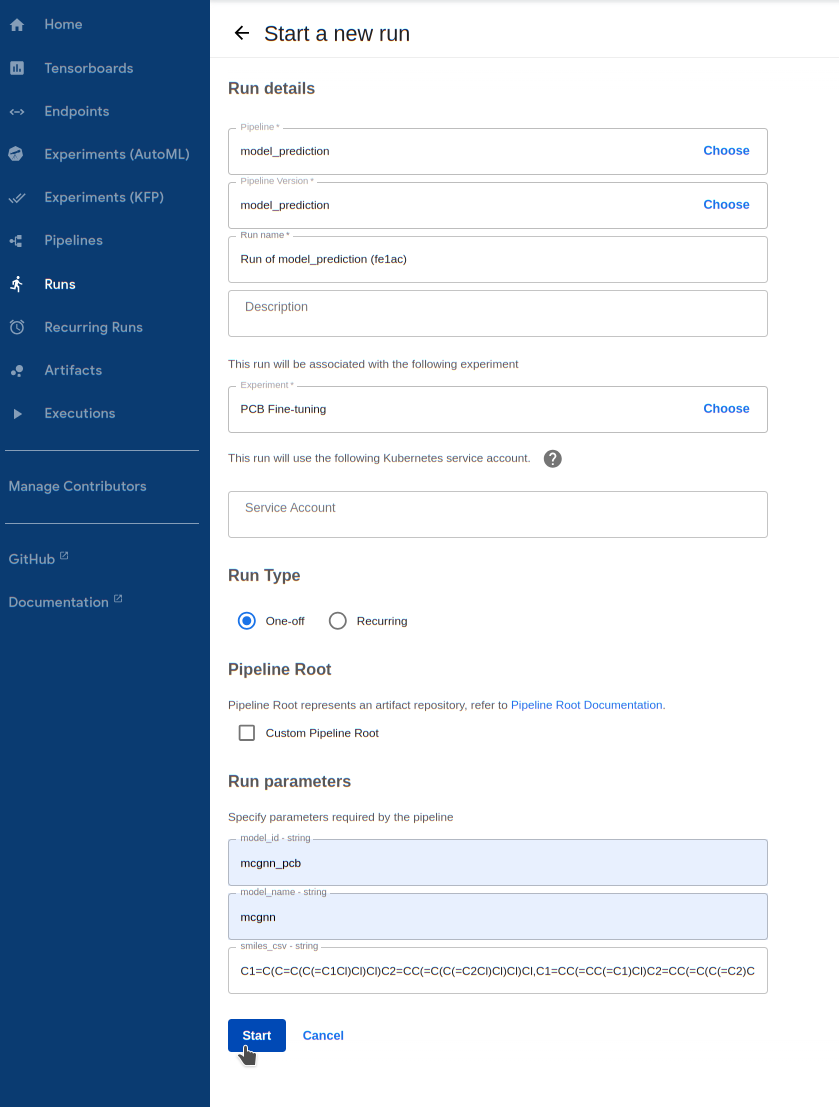
Run the prediction pipeline
1.1. Go to
Runs -> Create run1.2. For
Pipeline, select themodel_predictionpipeline underSharedpipelines1.3. For
Experiment, select the experiment you created earlier1.4. Enter your model's ID in
model_id. If you wanted to run prediction on a pre-trained
model without fine-tuning, you can choose from delfta and mcgnn for this field
1.5. Choose the `model_name` you fine-tuned earlier, between `mcgnn` or `delfta`. We trained a MCGNN model in this tutorial
1.6. Enter the PCB SMILES list above for `smiles_csv`
1.7. Finally, hit `Start` to kick it off!
-
Wait for the prediction procedure to complete and display a green mark on the following component. If the pipeline fails (likely due to invalid input), click on the failed component and view its
Logsto see the error message. Note that amodeloutput shows up here, but this is just because the model data is downloaded onto the Kubeflow worker for prediction
-
See the predicted HOMO-LUMO Gap for each molecule! We can see this by clicking on the
predictcomponent and looking at theOutput: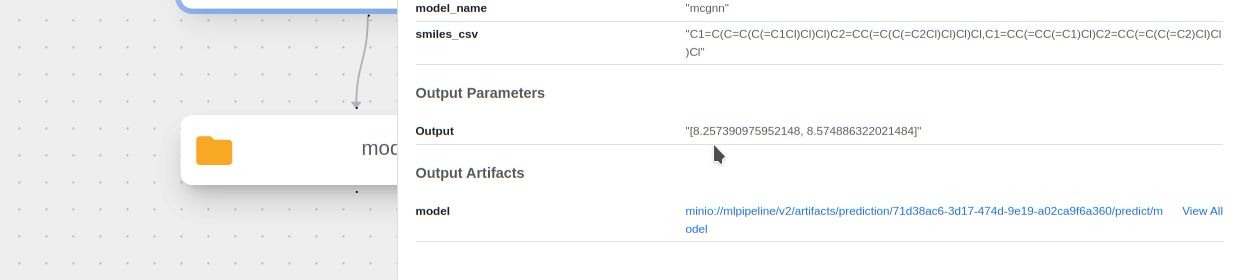
-
The actual HL gap values for these PCBs are 8.23 eV and 8.57 eV respectively. It makes sense that the model predicted extremely well with these as they are in the training data.
Generative Adversarial Network (GAN)¶
The MQS GAN framework is currently being tested and then utilized for production in various industrial projects. More information will follow when the testing phase and production deployment has been completed.
-
Kenneth Atz, Clemens Isert, Markus N. A. Böcker, José Jiménez-Luna, and Gisbert Schneider. Δ-quantum machine-learning for medicinal chemistry†. Physical Chemistry Chemical Physics, 24(18):10775–10783, 2022. doi:10.1039/d2cp00834c. ↩↩
-
Maho Nakata, Tomomi Shimazaki, Masatomo Hashimoto, and Toshiyuki Maeda. Pubchemqc pm6: data sets of 221 million molecules with optimized molecular geometries and electronic properties. Journal of Chemical Information and Modeling, 60(12):5891–5899, 2020. doi:10.1021/acs.jcim.0c00740. ↩↩
-
Clemens Isert, Kenneth Atz, José Jiménez-Luna, and Gisbert Schneider. Qmugs, quantum mechanical properties of drug-like molecules. Scientific Data, 9(1):273, 2022. doi:10.1038/s41597-022-01390-7. ↩↩